C# Dictionary 底层原理深度解析:从结构到实战(含 Java HashMap 对比 + 高频问题)
核心对比(简易版):
C# Dictionary 和 Java HashMap 的底层都是哈希表,且都采用拉链法处理哈希冲突,但两者的实现机制存在根本性差异,特别是在数据存储方式上:
-
Java HashMap:采用「多链表拉链法」——
table数组既管哈希又存数据,每个数组元素是独立的Node对象,哈希冲突时通过对象引用串联成多条独立链表(Java 8+ 链表过长转红黑树)。 -
C# Dictionary:采用「单数组拉链法」—— 创新性地使用双数组设计:
buckets数组(int[])仅负责哈希处理和冲突索引管理;entries数组(存储Entry结构体)作为唯一的数据存储容器,所有键值对统一存储在这一个数组中;- 哈希冲突时,通过
entries数组中每个元素的Next字段(整数索引)串联成逻辑上的链表,而非物理上的独立链表。
关键澄清:虽然都叫「拉链法」,但C# Dictionary的实现与传统哈希表的拉链法有所不同。传统拉链法通常需要每个哈希桶对应一条独立链表,而C# Dictionary通过单个数组+整数索引的方式,在一个连续内存块中模拟出了多条逻辑链表,既保留了拉链法的冲突处理能力,又优化了内存使用和访问效率。
一、底层核心原理:哈希表 + 双数组 + 头插法
Dictionary<TKey, TValue>的底层本质是哈希表(Hash Table),核心设计是 “双数组 + 头插法拉链法”。关键结论:双数组中,仅buckets数组承担哈希表的核心逻辑(哈希映射、冲突链表的索引管理),entries数组仅作为统一的数据存储容器,所有哈希相关的处理均与buckets数组强绑定。
1. 核心内部结构:双数组分工明确
-
buckets数组(哈希处理的核心载体):-
类型:
int[],长度始终为 2 的幂(优化位运算取模效率); -
核心作用:
-
-
接收哈希码映射后的桶索引,作为 “哈希桶” 的唯一标识;
-
存储每个哈希桶对应的冲突链表头节点索引(指向
entries数组的下标),管理逻辑链表的串联关系;
-
本质:哈希表的 “索引目录”,所有哈希相关逻辑(哈希映射、冲突处理入口)均在此发生。
-
entries数组(纯数据存储容器):-
类型:存储
Entry结构体的数组,是 Dictionary 唯一的数据存储区,不参与哈希计算或映射,仅按索引存储键值对; -
Entry结构体核心字段(简化版源码):
-
1
2
3
4
5
6
7
private struct Entry
{
public int HashCode; // 键的哈希码(非负处理后,仅用于快速筛选,不参与映射)
public int Next; // 下一个冲突元素的entries索引(-1表示链表尾,仅用于串联逻辑链表)
public TKey Key; // 存储的键(唯一标识)
public TValue Value; // 存储的值
}
-
关键说明:
Next字段是整数索引(非对象引用),仅用于将同一哈希桶的元素串联,不参与哈希处理。 -
辅助字段:
-
_nextFreeIndex:计数器,按顺序分配entries数组的空闲下标(新增元素时使用); -
_freeList:空闲链表,复用删除元素后的entries下标(优化内存利用率); -
负载因子:默认 0.72(微软测试的黄金平衡点,平衡冲突率与内存利用率)。
-
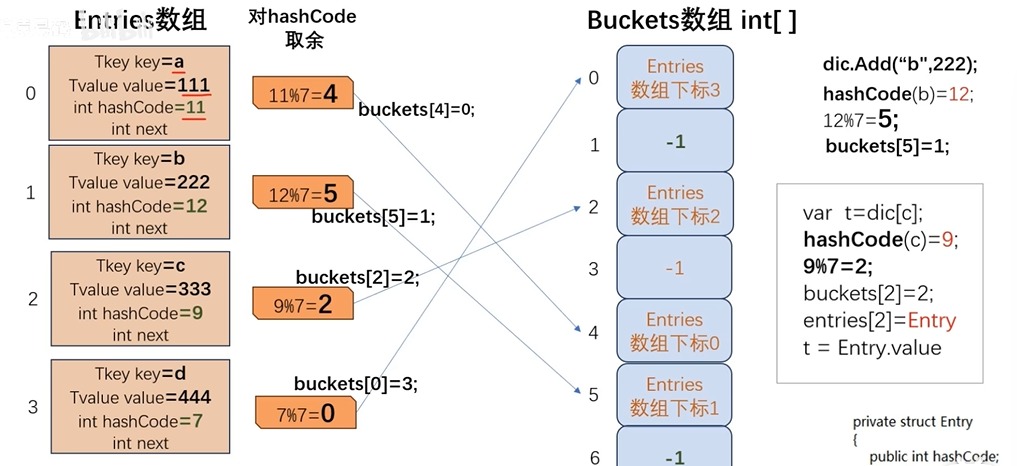 Csharp Dictionary 双数组结构示意图:buckets 数组管理哈希索引,entries 数组存储键值对数据
Csharp Dictionary 双数组结构示意图:buckets 数组管理哈希索引,entries 数组存储键值对数据
2. 核心工作流程:以 Add 操作为例(哈希处理仅关联buckets)
当调用dict.Add(key, value)时,哈希相关处理仅发生在buckets数组层面,entries仅负责存储数据,流程如下:
步骤 1:计算哈希码并优化
调用key.GetHashCode()获取原始哈希码,通过位运算消去符号位(确保非负):
1
int hashCode = key.GetHashCode() & 0x7FFFFFFF; // 避免负数索引
步骤 2:哈希映射到buckets数组(核心哈希逻辑)
将处理后的哈希码对buckets长度取模(因长度为 2 的幂,简化为位运算),得到桶索引:
1
int bucketIndex = hashCode & (buckets.Length - 1); // 等价于hashCode % buckets.Length
这一步是哈希表的核心映射逻辑,仅与buckets数组相关。
步骤 3:处理哈希冲突(buckets管理索引,entries存储数据)
采用头插法的拉链法处理冲突,核心是buckets对entries索引的管理:
- 若
buckets[bucketIndex] = -1(空桶):
-
将新元素存入
entries[_nextFreeIndex]; -
更新
buckets[bucketIndex] = _nextFreeIndex(桶指向数据索引); -
_nextFreeIndex++。
- 若
buckets[bucketIndex] != -1(冲突):
-
遍历该桶的逻辑链表(通过
entries[].Next索引),用key.Equals(现有键)校验是否重复; -
若重复,抛出
ArgumentException(“已添加了具有相同键的项”); -
若不重复,将新元素存入
entries空闲下标,新元素的Next设为原链表头(buckets[bucketIndex]),再更新buckets[bucketIndex]为新元素下标(新元素成为链表头)。
示例演示:添加 “A”→”B”→”C”(均冲突到桶 1)
-
添加 “A”:
buckets[1] = 0,entries[0].Next = -1; -
添加 “B”:
entries[1].Next = 0,buckets[1] = 1(链表:1→0); -
添加 “C”:
entries[2].Next = 1,buckets[1] = 2(链表:2→1→0)。
步骤 4:扩容判断与执行
当元素数量Count超过 “容量 ×0.72” 时,触发扩容:
-
新建容量为原 2 倍的
buckets和entries数组; -
重新计算所有元素的哈希码,映射到新
buckets数组(仅与buckets相关的哈希重映射); -
替换原数组,完成扩容(时间复杂度 O (n),但通过负载因子控制扩容频率)。
3. 关键设计细节:为什么这么设计?
-
头插法优势:无需遍历链表(O (1) 操作),比尾插法(O (k),k 为链表长度)性能更优;
-
双数组分工:
buckets专注哈希处理,entries专注数据存储,兼顾哈希表的高效性与数组的内存紧凑性; -
负载因子 0.72:平衡冲突率(过低导致冲突剧增)与内存利用率(过高导致内存浪费)。
二、C# Dictionary vs Java HashMap:核心差异(简易版)
| 对比维度 | C# Dictionary<TKey, TValue> | Java HashMap(Java 8+) |
|---|---|---|
| 核心数组 | 双数组(buckets管哈希,entries存数据) |
单数组(table既管哈希又存数据) |
| 数据存储 | 连续结构体数组,整数索引串联冲突元素 | 独立Node对象,引用串联冲突链表 |
| 冲突处理 | 逻辑链表(始终不变) | 物理链表,过长转红黑树 |
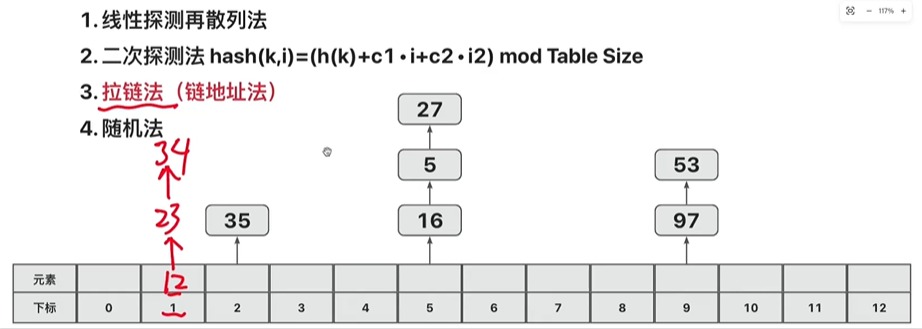
Java HashMap 单数组结构示意图:table 数组既管理哈希索引,又存储键值对数据,使用 Node 对象引用串联冲突元素
三、高频问题及标准答案
追问 1:Dictionary 的双数组中,哪个真正参与哈希处理?为什么?
答案:
仅buckets数组参与哈希处理,entries只存数据。原因:
-
buckets接收哈希码映射后的桶索引,是哈希桶的核心标识; -
buckets存储冲突链表的头索引,管理冲突处理入口; -
entries仅按索引存储键值对,其Next字段仅用于串联逻辑链表,不参与哈希计算或映射。
追问 2:Dictionary 如何处理哈希冲突?和 Java HashMap 有何区别?
答案:
C# 用头插法的逻辑链表(buckets管索引,entries存数据,靠整数索引串联);
Java 用物理链表(Node引用串联),Java 8 后链表过长转红黑树;
核心区别:C# 是 “双数组 + 索引”,Java 是 “单数组 + 节点引用”。
追问 3:插入重复键为何抛出异常?
答案:
Dictionary 要求键唯一,冲突时会遍历对应桶的链表,用key.Equals(现有键)校验,相同则抛异常(哈希冲突是 “不同键同哈希”,会串联;键重复是 “相同键”,直接抛异常)。
询问 4:自定义类型作为键,需要满足什么条件?
答案:
必须同时重写GetHashCode()和Equals()方法,且遵守规范:
-
若
a.Equals(b) = true,则a.GetHashCode() = b.GetHashCode()(确保相同键映射到同一桶); -
若
a.GetHashCode() = b.GetHashCode(),a.Equals(b)可返回 false(允许哈希冲突)。
询问 5:Dictionary 是线程安全的吗?如何实现线程安全?
答案:
非线程安全,多线程读写会抛出异常或数据错乱; 线程安全方案(优先级从高到低):
-
ConcurrentDictionary<TKey, TValue>:.NET 官方推荐,分段锁(细粒度锁),高并发性能好; -
手动 lock:用 lock 包裹所有操作(粗粒度锁,高并发性能差);
-
Hashtable 的
Synchronized包装类:非泛型,性能差,不推荐。
询问 6:HashSet 的关系?
答案:
底层实现完全一致(双数组 + 头插法),HashSet 是 Dictionary 的 “键集简化版”:
-
Dictionary 的
entries存储Key+Value,核心功能是键值映射; -
HashSet 的
entries仅存储元素(等价于 Dictionary 的 Key),无 Value 字段,核心功能是去重、快速判重、集合运算(交集 / 并集等)。
询问 7:C# Dictionary 为何不像 Java HashMap 那样转红黑树?
答案:
-
底层结构限制:C# 是逻辑链表(靠整数索引),转红黑树需增加大量字段,内存开销太大;
-
设计理念:.NET 通过 0.72 负载因子保证链表长度极短(多数≤3),遍历开销可忽略,无需红黑树优化;
-
替代方案存在:.NET 有
SortedDictionary<TKey, TValue>(底层红黑树),专门用于有序场景。
四、关键补充:逻辑链表的本质(数组 vs 链表的混合设计)
C# Dictionary 的 “逻辑链表” 是「数组物理存储 + 链表逻辑行为」的混合结构:
-
物理存储:是纯粹的数组 ——
entries是连续内存块,元素按下标直接访问(O (1)),内存紧凑; -
逻辑行为:表现为链表 —— 通过
Next索引顺序访问冲突元素,动态修改串联关系,无需改变数组物理顺序; -
设计优势:兼具数组的高缓存命中率和链表的冲突处理灵活性,规避纯数组的扩容移动开销和纯链表的内存碎片化问题。
五、总结
C# Dictionary 的底层设计是 “分工明确 + 高效平衡” 的典范:
-
核心分工:
buckets数组承担所有哈希处理(映射、冲突管理),entries数组专注数据存储; -
性能特性:平均 O (1) 增删改查,最坏 O (n)(极端哈希冲突);
-
与 Java HashMap 的核心差异:仅在于 “双数组 vs 单数组”“索引串联 vs 节点引用串联”,本质是语言特性和设计理念导致的。